参考文献:https://post.smzdm.com/p/arqxo33g/
感谢大佬文章救我数据狗命🤝
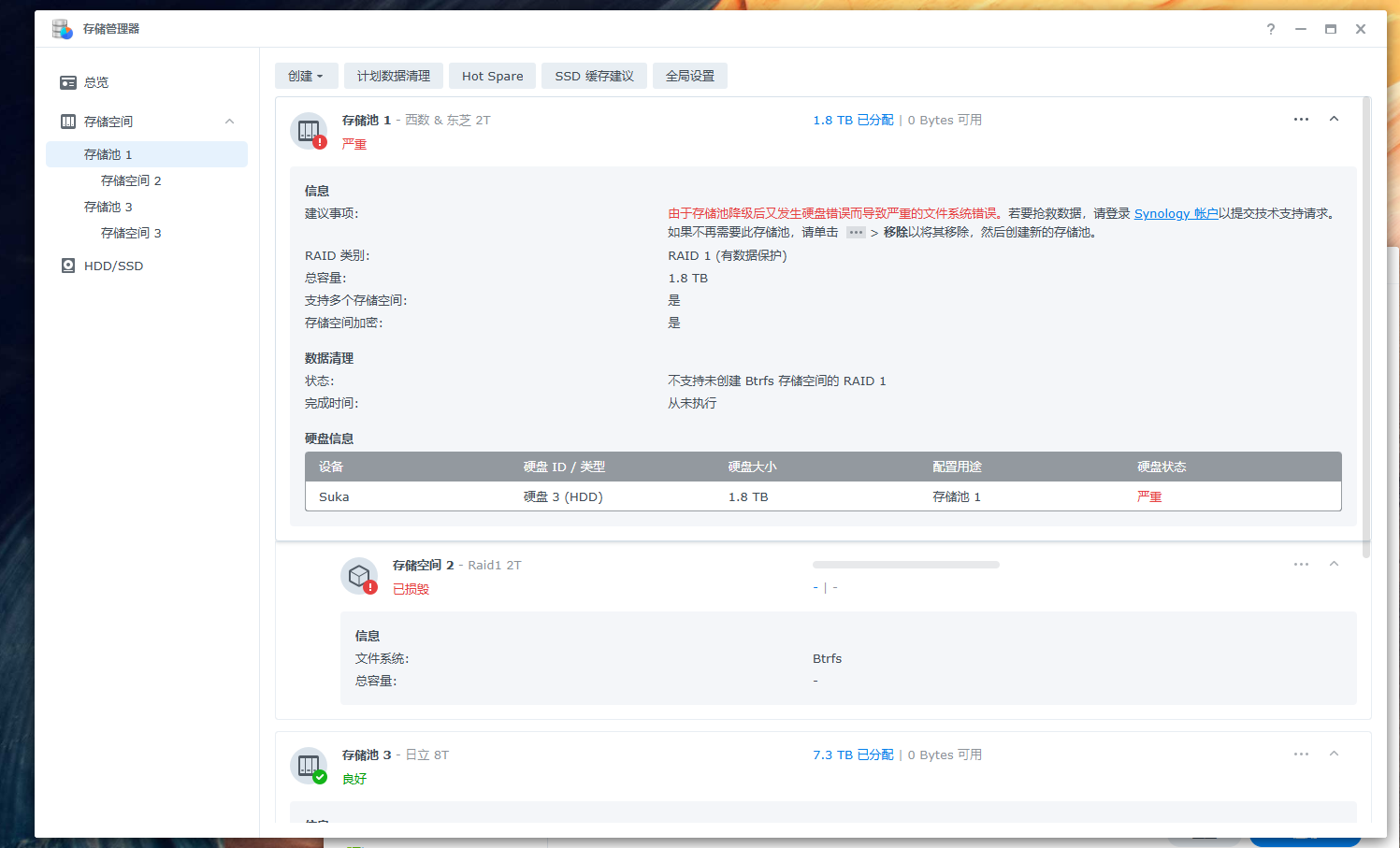
警告:硬盘拯救成功 此操作后存储空间我这里在校验后依旧损毁 请勿操作 仅供参考。
警告:硬盘拯救成功 此操作后存储空间我这里在校验后依旧损毁 请勿操作 仅供参考。
警告:硬盘拯救成功 此操作后存储空间我这里在校验后依旧损毁 请勿操作 仅供参考。
环境
黑群晖RR引导,SA6400,DSM 7.2.2-72806 Update 3,设备移动位置顺便拆开简单清灰(我甚至都没有碰硬盘,只是清理了外面的防尘网),断电后所有外置线缆重新连接后提示空间降级,硬盘损毁。尝试重新拔插sata线后损毁的直接变新硬盘了,还一起喜提了同组的另一块硬盘无法访问系统分区。

我甚至不是第一次碰到这件事情了,之前也遇到过很多很多很多很多很多次系统损毁,并且是莫名其妙的,只要一断电挪一下就损毁,我不知道是黑群晖的原因还是群晖原本就如此令人费解。之前都是直接硬着头皮同步修复,今天两块一起炸了修复不了了,无奈开始寻找办法。
着手解决
ssh以root身份登录群晖。
使用sudo fdisk -l | grep sata1来查看并过滤指定硬盘的信息。sata后的数字可以发生更改。
注意:此处sata号并不等同于你在存储池子看到的硬盘号,你可能需要一些方式寻找到你要的那一块硬盘,我的顺序是按照主板上的sata序号的。或许你可以查看后文通过阵列异常来判断异常sata序号。
Disk /dev/sata4: 1.8 TiB, 2000398934016 bytes, 3907029168 sectors
/dev/sata4p1 2048 4982527 4980480 2.4G fd Linux raid autodetect
/dev/sata4p2 4982528 9176831 4194304 2G fd Linux raid autodetect
/dev/sata4p3 9437184 3906824351 3897387168 1.8T fd Linux raid autodetect(这里是我已经修复磁盘后演示的 此处每行最后的描述有可能是不同的)
这里可以看到sata4p1和sata4p2为群晖系统分区所在处。
使用cat /proc/mdstat查看群晖阵列情况!
md2 : active raid1 sata3p3[2] sata4p3[3]
1948692544 blocks super 1.2 [2/1] [_U]
[====>................] recovery = 22.2% (433633472/1948692544) finish=231.0min speed=109302K/sec
md4 : active raid1 sata2p3[0]
7809204544 blocks super 1.2 [1/1] [U]
md1 : active raid1 sata3p2[0] sata2p2[4] sata4p2[1]
2097088 blocks [12/3] [UU__U_______]
md0 : active raid1 sata3p1[0] sata4p1[2] sata2p1[1]
2490176 blocks [12/3] [UUU_________]
unused devices: <none>(这里是我已经修复磁盘后演示的 这里的分区已经修复完毕)
需要倒序分析这个文本。md0和md1即为系统分区所在阵列。其他需要通过分区观察是你设置的哪个阵列。
如果是无法访问系统分区则为p1和p2掉盘了,如果是损毁可能是一整个盘所有分区都掉出阵列了。
比如你的sata4p1和sata4p2出现异常,附带数据分区sata4p3,没有出现在阵列中(或许你也可以通过这个方法来确定前文的sata序号是多少)。
注意:以下内容是无保护,切实在分区中重建阵列的操作。操作前需要三思再三思,反复检查有无对错。重建阵列若出现差错,数据飞灰烟灭。
群晖无法访问系统分区实际上是异常硬盘的p1和p2分区从群晖自带的系统阵列中掉出。因为断电等原因硬盘没有实际损毁导致的硬盘莫名其妙异常损毁就我目测也是由于从给定的数据阵列中意外掉出。所以我们手动将它加入阵列,即可恢复这个问题。
将sata4掉出的分区全部加回到阵列中去,其他硬盘同理。(madam需要使用sudo执行)
注意!!!仔细检查阵列是否对应。示例:
sudo mdadm -a /dev/md0 /dev/sata4p1sudo mdadm -a /dev/md1 /dev/sata4p2sudo mdadm -a /dev/md2 /dev/sata4p3如果提示mdadm: added /dev/sata4p1即为执行成功。
检查群晖储存管理,硬盘立刻变绿,存储池如果严重损毁可能跟我一样需要进入数据检查阶段。
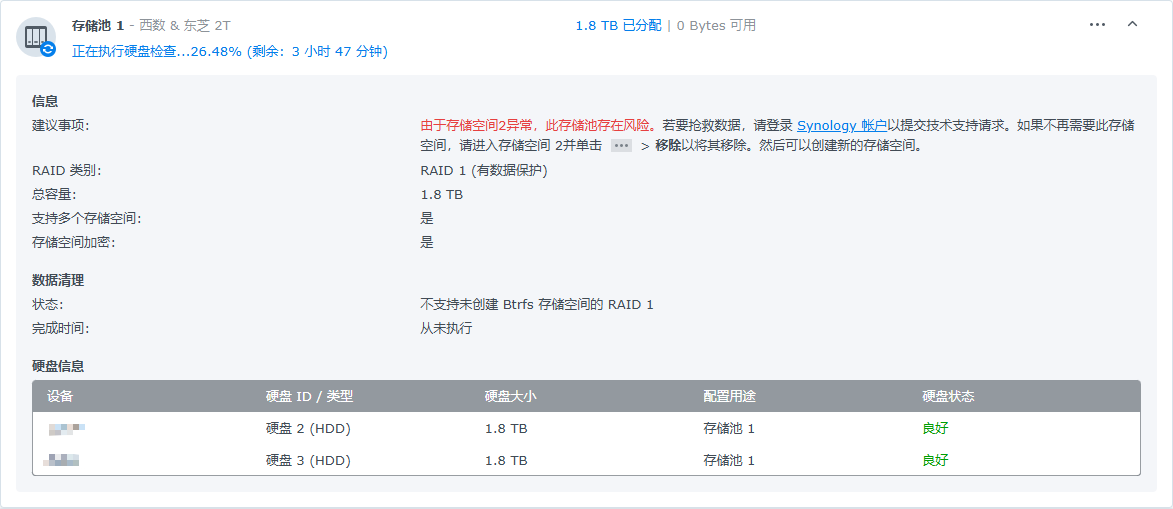
至此耐心等待,硬盘应当可以恢复,但是存储空间依旧损毁。
写在最后
令人不可置信的是,其实我已经遇到这个问题少说有五六次了,不知道是不是黑群晖的问题才这么多次,但是据我观测白群晖的用户也有时候会遇到这个问题。原因不详,是和盘的稳定性有关吗?我有一块企业矿盘日立的8T,每次掉盘好像就没它的事情。我也不清楚。
之前我的解决方式都是损毁的就让按部就班群晖格式化后全部重建,无法访问系统分区的就按照群晖方式慢慢修复。但是这次raid1两个盘一个无法访问还修复失败,一修复就损毁,另外一个损毁后重新拔插直接变成新盘了,完全脱离了系统,实在是让我束手无策了。我不知道是因为群晖对硬盘要求高的问题吗,我使用下来这个问题遇到过很多很多次,貌似也没有那么的“稳定”。
不过这次也算是找到解决方案了,特此记录。
不知道群晖官方怎么看这么问题,正如原教程所说,其实这是一个特别简单的问题,就是阵列不知道为什么掉出来了而已。但是用户遇到就有数据爆炸的风险,解决方式却那么那么少,其实可以研究一下给一个失去大脑的傻瓜解决方案的。